Treine modelos ML de produção em minutos
AutoML multi-engine com H2O e FLAML. Seleciona algoritmos automaticamente, ajusta hiperparâmetros e constrói ensembles empilhados — com orquestração paralela de motores para planos Enterprise.
De dados brutos a modelo de producao em tres passos
Sem engenharia de features manual, ajuste de hiperparametros ou selecao de algoritmos. O AutoML gerencia todo o pipeline.
1. Envie seus Dados
Arraste e solte arquivos CSV, Excel, JSON ou XML. A plataforma detecta automaticamente os tipos de coluna, identifica a variavel alvo e perfila seus dados em busca de problemas de qualidade.
2. Configure e Treine
Selecione a coluna alvo e o tipo de problema (classificacao ou regressao). O AutoML testa 50+ algoritmos com otimizacao bayesiana de hiperparametros e ensembles empilhados.
3. Avalie e Implante
Revise o ranking de modelos com metricas, explicacoes SHAP e importancia de features. Implante o melhor modelo em producao com um clique via MLOps.
Key Capabilities
Everything you need to get the most out of this module.
Seleção Automática de Algoritmos
50+ algoritmos testados automaticamente. XGBoost, GBM, deep learning, GLM e mais — o motor escolhe o melhor para seus dados.
Ajuste de Hiperparâmetros
A otimização bayesiana encontra hiperparâmetros ótimos mais rápido que busca em grade ou aleatória.
Ensembles Empilhados
Combina múltiplos modelos em ensembles poderosos que superam qualquer algoritmo individual.
Aceleração GPU
Aproveite computação GPU para treinamento mais rápido em datasets grandes. Retorno automático para CPU quando necessário.
50+ algoritmos testados automaticamente
O motor H2O.ai avalia dezenas de algoritmos e escolhe os melhores para a distribuicao especifica dos seus dados.
XGBoost
Arvores de decisao com gradient boosting otimizadas para velocidade e desempenho. Lida com valores ausentes nativamente e suporta aceleracao GPU.
Gradient Boosting (GBM)
Metodo de ensemble sequencial que constroi arvores corrigindo erros anteriores. Excelente para dados tabulares com interacoes complexas de features.
Deep Learning
Redes neurais multicamadas com arquiteturas configuraveis. Regularizacao automatica, dropout e early stopping para estabilidade em producao.
Random Forest (DRF)
Ensemble paralelo de arvores de decisao com bagging. Robusto contra overfitting e fornece rankings confiaveis de importancia de features.
Generalizado Linear (GLM)
Modelos lineares interpretaveis com regularizacao (L1/L2). Ideal quando a explicabilidade do modelo e um requisito regulatorio.
Ensembles Empilhados
Meta-aprendiz que combina predicoes de todos os modelos treinados. Tipicamente alcanca o melhor desempenho aproveitando a diversidade de modelos.
Treine modelos via codigo
Use o Python SDK para automatizar seus pipelines de treinamento. Gestao completa de experimentos, desde o upload de dados ate as explicacoes SHAP.
from coreplexml import CorePlexMLClient
client = CorePlexMLClient(
base_url="https://api.coreplexml.io",
api_key="sk_your_api_key"
)
# Upload training data
dataset = client.datasets.upload(
project_id="proj_abc",
file_path="customers.csv",
name="Customer Churn Data"
)
# Start AutoML training — 50+ algorithms tested
experiment = client.experiments.create(
project_id="proj_abc",
dataset_version_id=dataset["dataset_version_id"],
target_column="churn",
problem_type="classification",
config={"max_models": 20, "balance_classes": True}
)
# Wait for training to complete
result = client.experiments.wait(experiment["id"], timeout=3600)
print(f"Best model: {result['best_model_id']}")
print(f"AUC: {result['metrics']['auc']:.4f}")
# Get feature importance and SHAP values
explain = client.experiments.explain(experiment["id"])
for feat in explain["feature_importance"][:5]:
print(f" {feat['feature']}: {feat['importance']:.3f}")API de AutoML
Endpoints RESTful para gestao de experimentos, treinamento de modelos e predicoes.
/api/experimentsCriar e iniciar um novo experimento AutoML
/api/experiments/{id}/statusVerificar o progresso do treinamento e o estado atual
/api/experiments/{id}/explainObter importancia de features, valores SHAP e dados de explicabilidade
/api/experiments/{id}/notebookExportar experimento como notebook Jupyter
/api/models/{id}/predictRealizar predicoes usando um modelo treinado
/api/models/{id}Obter detalhes do modelo, metricas e hiperparametros
Do experimento a analitica do modelo
Assistente de experimento AutoML de 4 passos
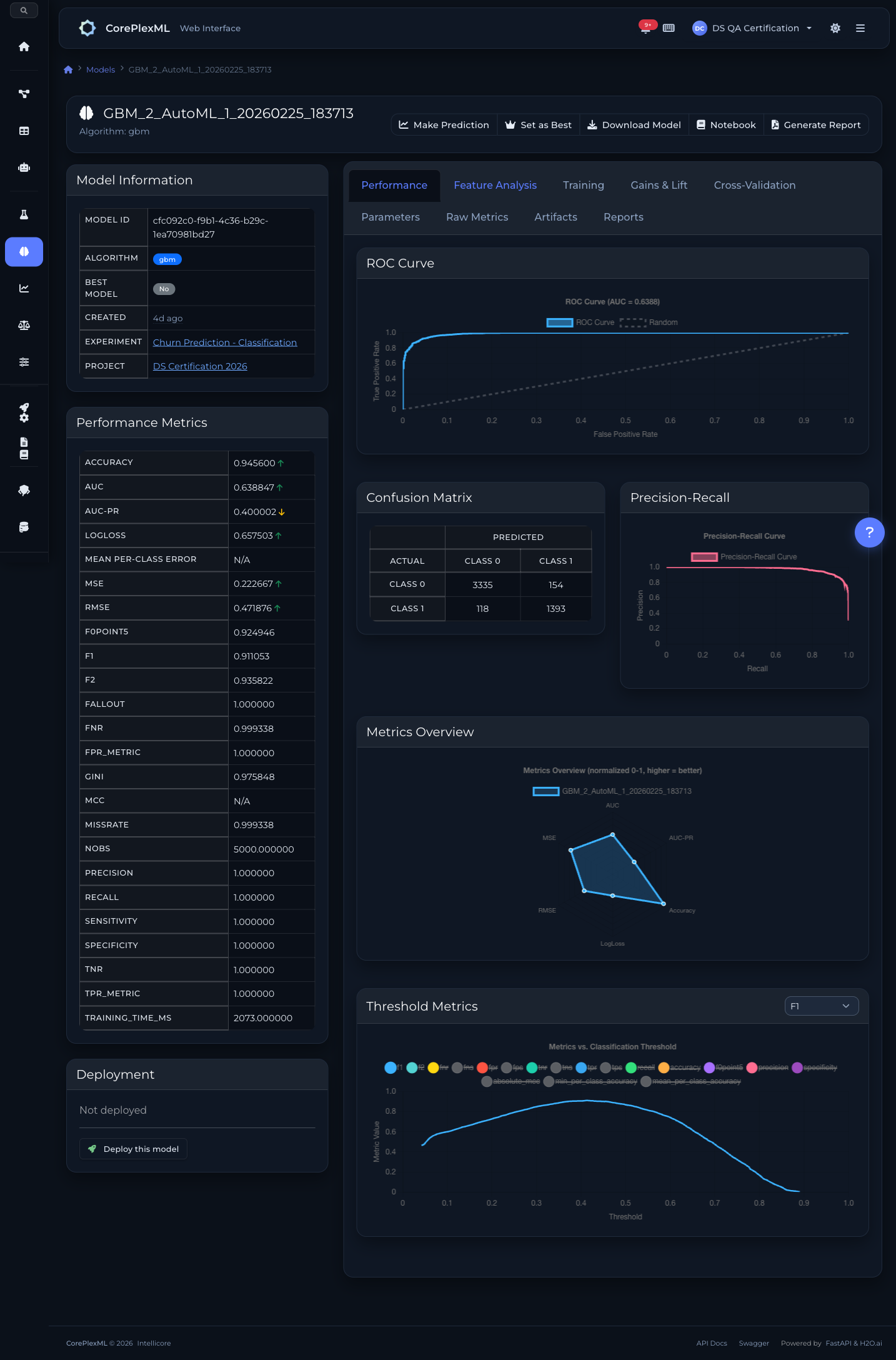
Curvas ROC, matriz de confusao e precisao-recall
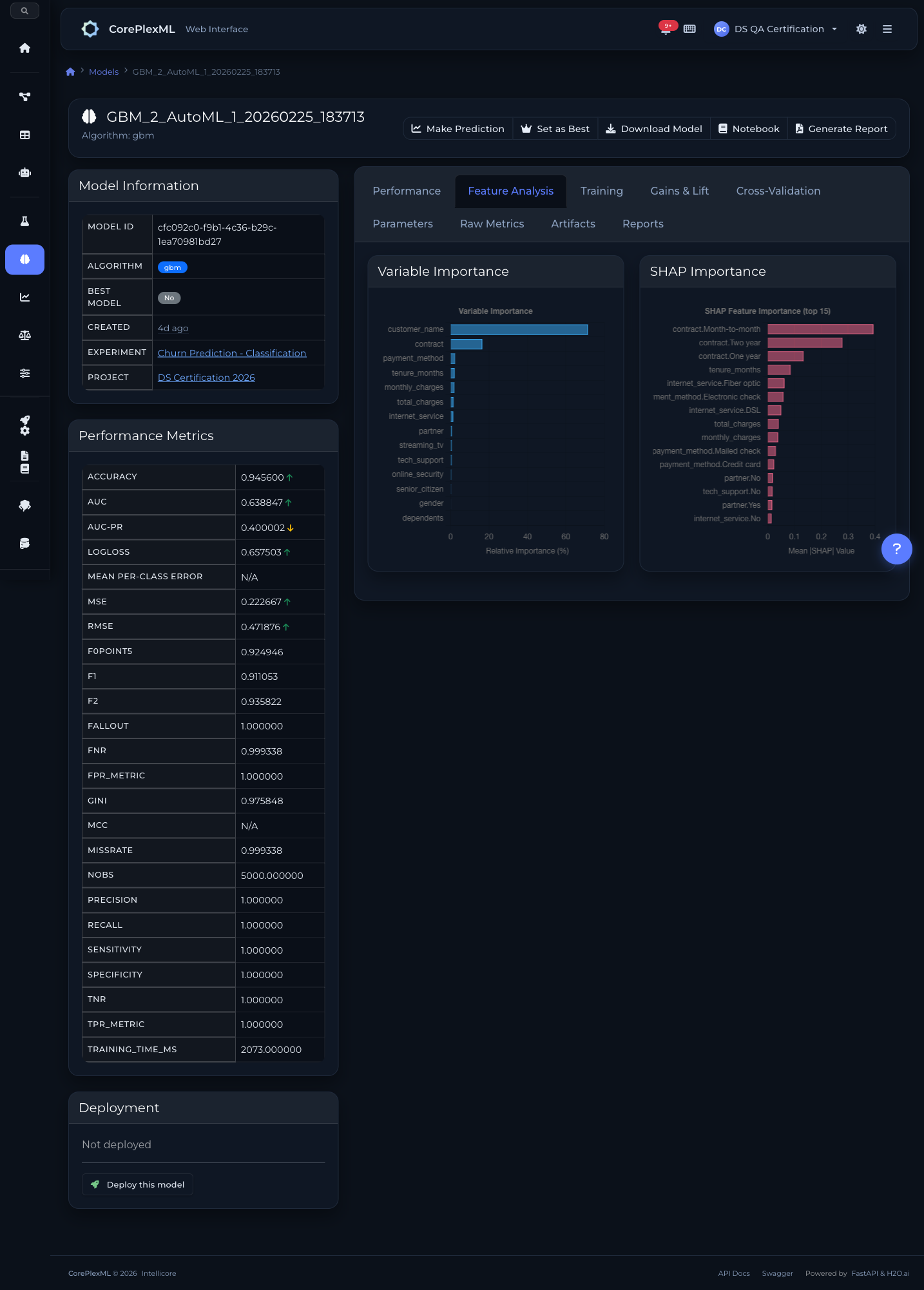
Valores SHAP e importancia de variaveis
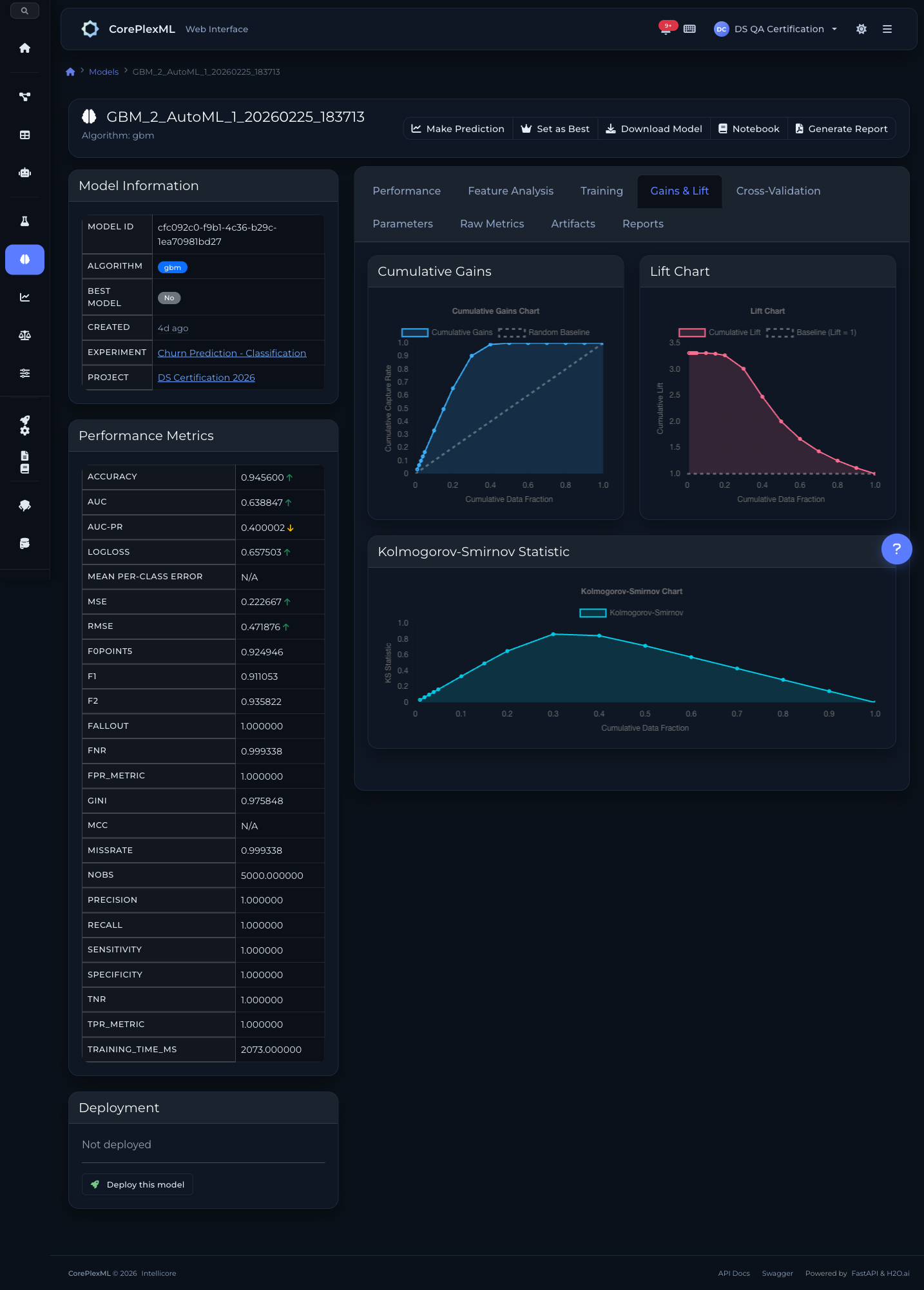
Ganhos acumulados, lift e estatisticas K-S
Pronto para comecar?
Comece a construir com CorePlexML hoje. Plano gratuito disponivel — nao e necessario cartao de credito.