Entrena modelos ML de producción en minutos
AutoML multi-engine con H2O y FLAML. Selecciona algoritmos automáticamente, ajusta hiperparámetros y construye ensembles apilados — con orquestación paralela de motores para planes Enterprise.
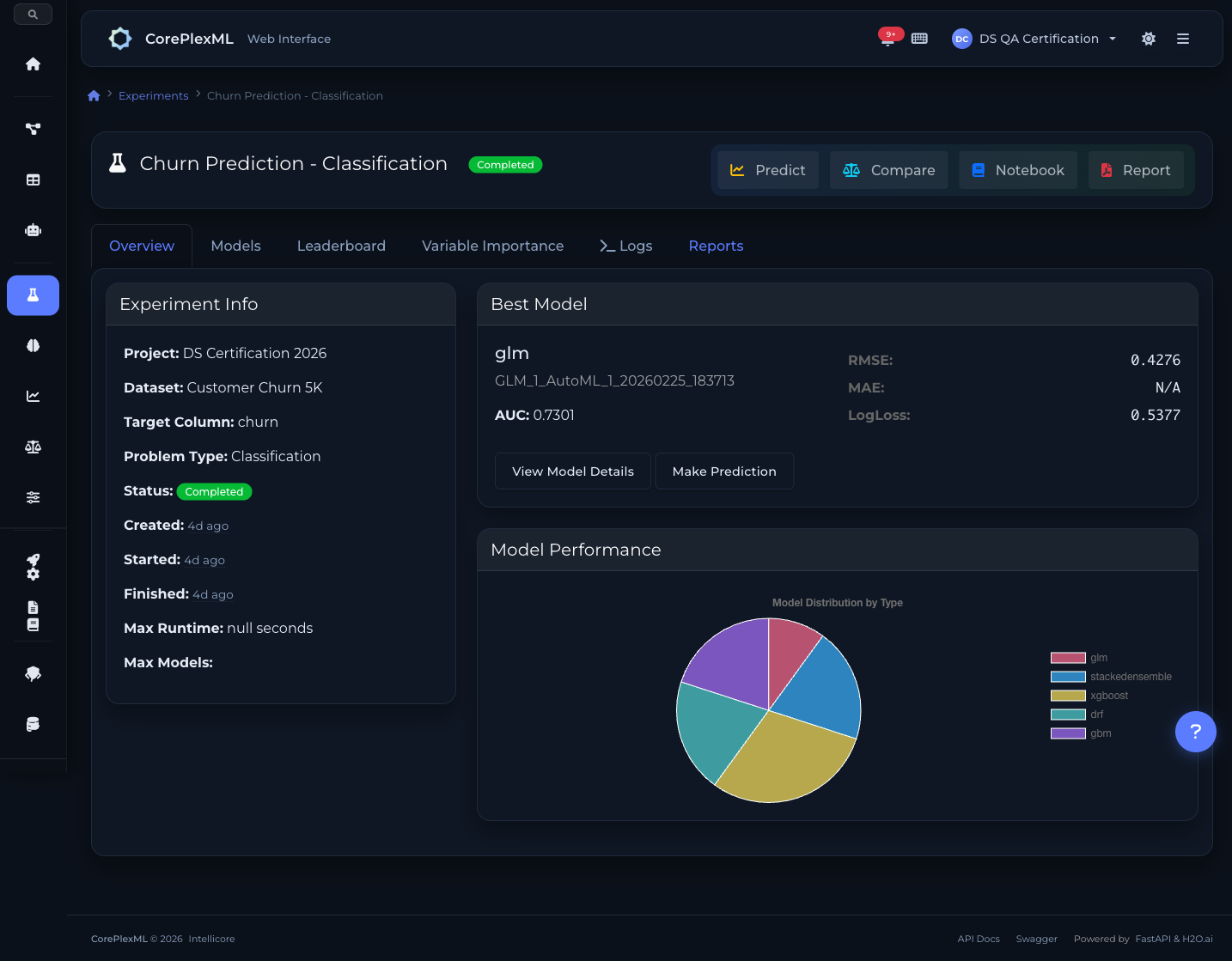
De datos brutos a modelo de producción en tres pasos
Sin ingeniería de features manual, ajuste de hiperparámetros ni selección de algoritmos. AutoML gestiona todo el pipeline.
1. Sube tus Datos
Arrastra y suelta archivos CSV, Excel, JSON o XML. La plataforma detecta automáticamente los tipos de columna, identifica la variable objetivo y perfila tus datos en busca de problemas de calidad.
2. Configura y Entrena
Selecciona la columna objetivo y el tipo de problema (clasificación o regresión). AutoML prueba 50+ algoritmos con optimización bayesiana de hiperparámetros y ensembles apilados.
3. Evalúa y Despliega
Revisa la tabla de clasificación de modelos con métricas, explicaciones SHAP e importancia de features. Despliega el mejor modelo a producción con un clic mediante MLOps.
Key Capabilities
Everything you need to get the most out of this module.
Selección Automática de Algoritmos
50+ algoritmos probados automáticamente. XGBoost, GBM, deep learning, GLM y más — el motor elige el mejor para tus datos.
Ajuste de Hiperparámetros
La optimización bayesiana encuentra hiperparámetros óptimos más rápido que búsqueda en cuadrícula o aleatoria.
Ensembles Apilados
Combina múltiples modelos en ensembles potentes que superan a cualquier algoritmo individual.
Aceleración GPU
Aprovecha cómputo GPU para entrenamiento más rápido en datasets grandes. Retorno automático a CPU cuando sea necesario.
50+ algoritmos probados automáticamente
El motor de H2O.ai evalúa decenas de algoritmos y elige los mejores para tu distribución de datos específica.
XGBoost
Árboles de decisión con gradient boosting optimizados para velocidad y rendimiento. Maneja valores faltantes de forma nativa y soporta aceleración GPU.
Gradient Boosting (GBM)
Método de ensemble secuencial que construye árboles corrigiendo errores anteriores. Excelente para datos tabulares con interacciones de features complejas.
Deep Learning
Redes neuronales multicapa con arquitecturas configurables. Regularización automática, dropout y early stopping para estabilidad en producción.
Random Forest (DRF)
Ensemble paralelo de árboles de decisión con bagging. Robusto contra overfitting y proporciona rankings de importancia de features confiables.
Generalizado Lineal (GLM)
Modelos lineales interpretables con regularización (L1/L2). Ideal cuando la explicabilidad del modelo es un requisito regulatorio.
Ensembles Apilados
Meta-aprendiz que combina predicciones de todos los modelos entrenados. Típicamente logra el mejor rendimiento aprovechando la diversidad de modelos.
Entrena modelos mediante código
Usa el Python SDK para automatizar tus pipelines de entrenamiento. Gestión completa de experimentos, desde la carga de datos hasta las explicaciones SHAP.
from coreplexml import CorePlexMLClient
client = CorePlexMLClient(
base_url="https://api.coreplexml.io",
api_key="sk_your_api_key"
)
# Upload training data
dataset = client.datasets.upload(
project_id="proj_abc",
file_path="customers.csv",
name="Customer Churn Data"
)
# Start AutoML training — 50+ algorithms tested
experiment = client.experiments.create(
project_id="proj_abc",
dataset_version_id=dataset["dataset_version_id"],
target_column="churn",
problem_type="classification",
config={"max_models": 20, "balance_classes": True}
)
# Wait for training to complete
result = client.experiments.wait(experiment["id"], timeout=3600)
print(f"Best model: {result['best_model_id']}")
print(f"AUC: {result['metrics']['auc']:.4f}")
# Get feature importance and SHAP values
explain = client.experiments.explain(experiment["id"])
for feat in explain["feature_importance"][:5]:
print(f" {feat['feature']}: {feat['importance']:.3f}")API de AutoML
Endpoints RESTful para gestión de experimentos, entrenamiento de modelos y predicciones.
/api/experimentsCrear e iniciar un nuevo experimento AutoML
/api/experiments/{id}/statusVerificar el progreso del entrenamiento y el estado actual
/api/experiments/{id}/explainObtener importancia de features, valores SHAP y datos de explicabilidad
/api/experiments/{id}/notebookExportar experimento como notebook Jupyter
/api/models/{id}/predictRealizar predicciones usando un modelo entrenado
/api/models/{id}Obtener detalles del modelo, métricas e hiperparámetros
Del experimento a la analítica del modelo
Asistente de experimento AutoML de 4 pasos
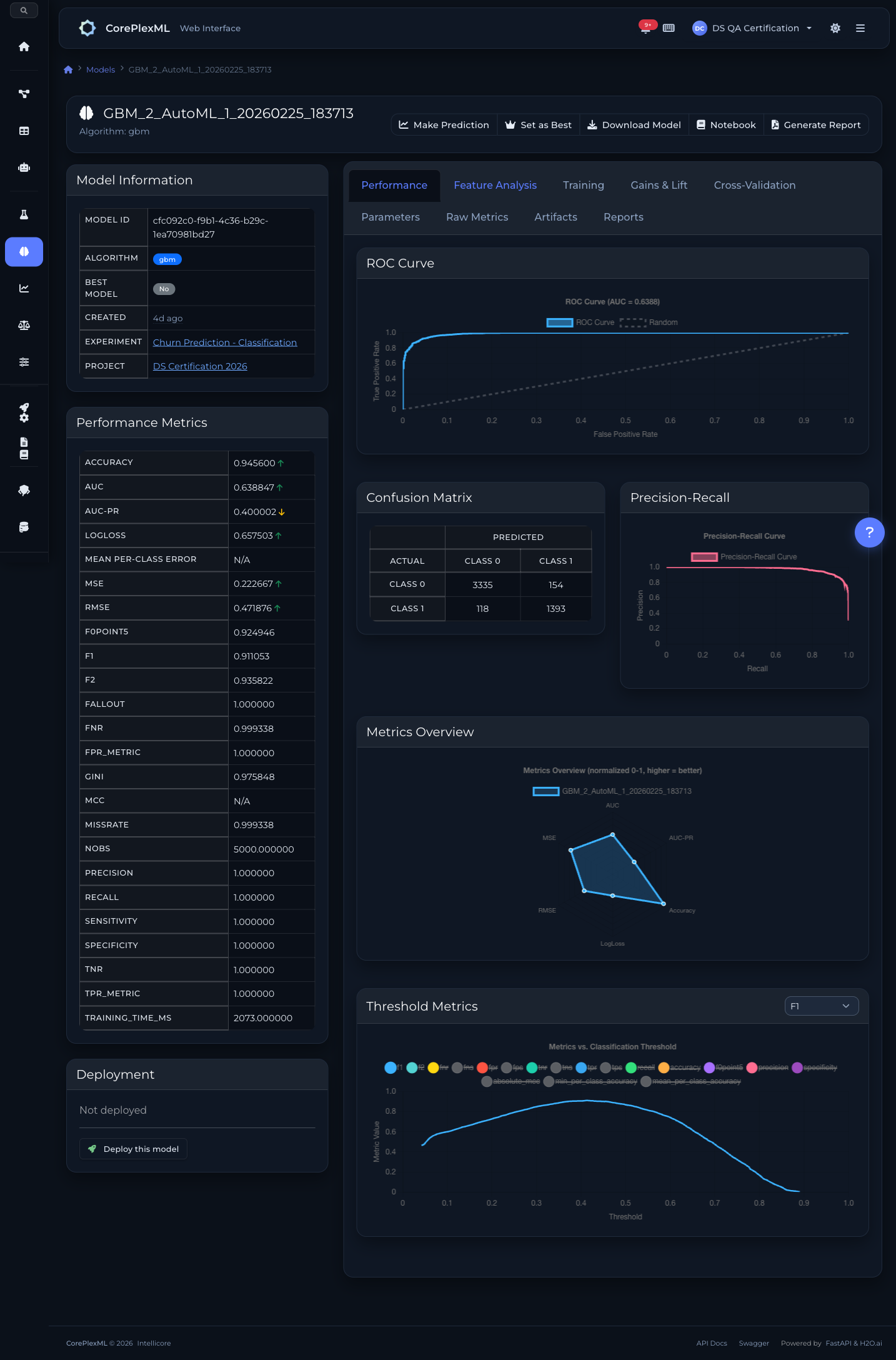
Curvas ROC, matriz de confusión y precisión-recall
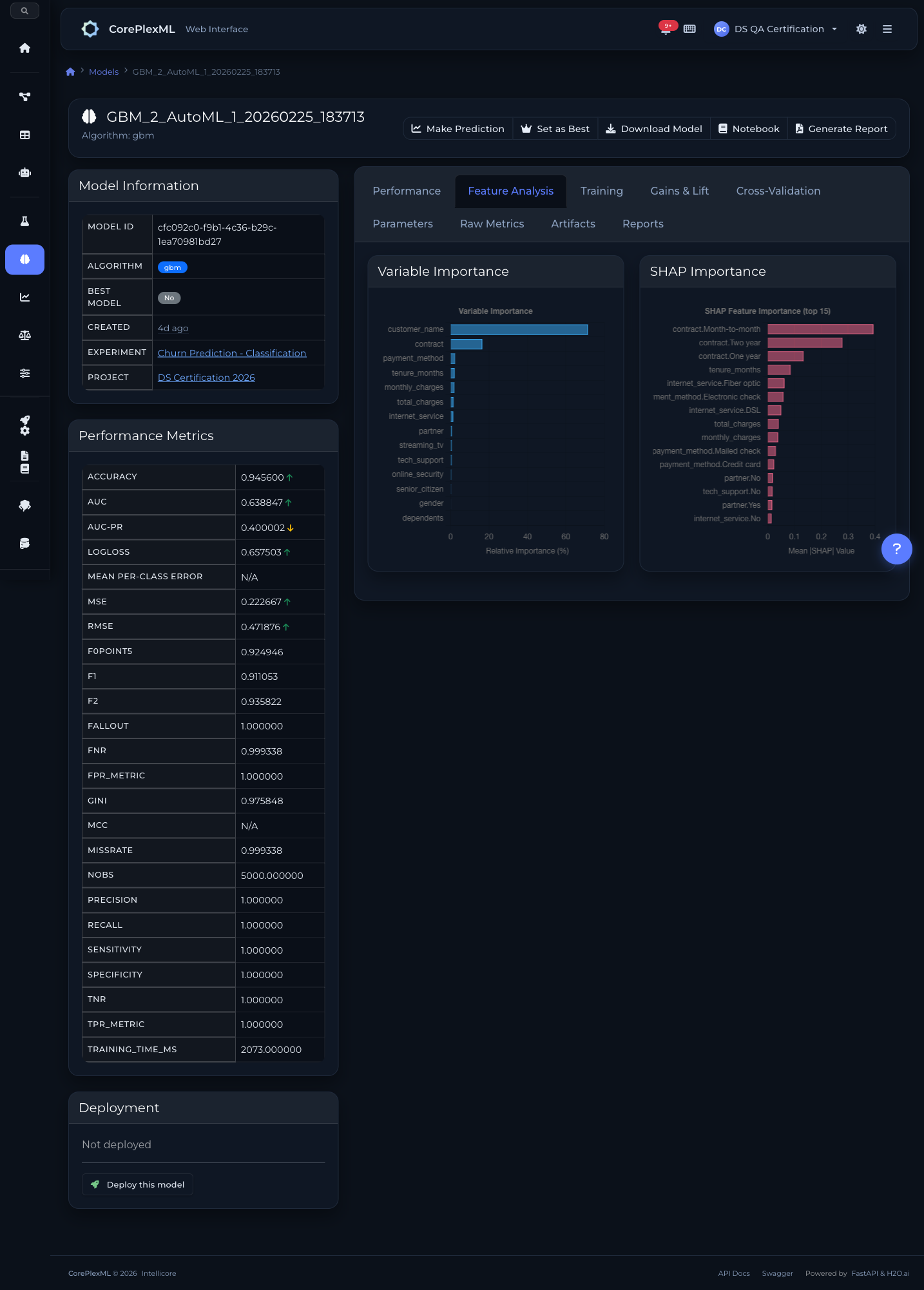
Valores SHAP e importancia de variables
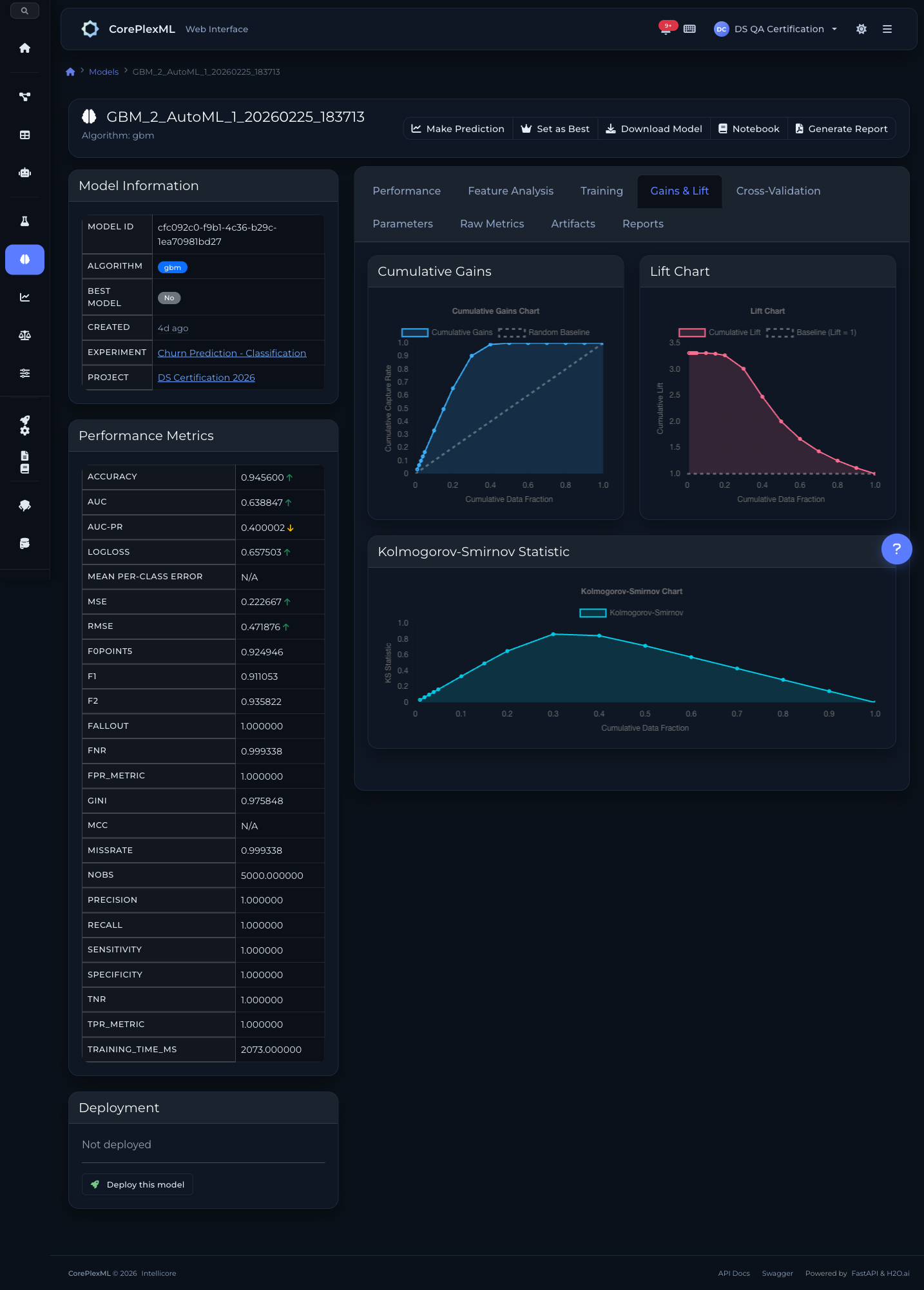
Ganancias acumuladas, lift y estadísticas K-S
¿Listo para empezar?
Empieza a construir con CorePlexML hoy. Nivel gratuito disponible — no se requiere tarjeta de crédito.